It’s no secret that healthcare is all the buzz these days. The US has the highest healthcare costs in the world. We have a new president elected by a large (relatively speaking) margin who put healthcare at the center of his platform. Major publications worldwide are suddenly interested in McAllen, Texas because of its extraordinary healthcare spending per capita. We’re operating in the worst economy most of us have (or will, hopefully) ever seen and the government just pledged billions for healthcare. If consultants are bees, healthcare is the latest honey.
What is particularly interesting to us of the analytical persuasion through all this is the totally awesome scale of data and analytics that are going to be needed if the US is ever going to come to grips with “the biggest threat to its balance sheet.” Obama got a standing-O and experienced his highest approval rating so far after stating “healthcare reform cannot wait, it must not wait, and it will not wait for another year”. It’s go time. So where do us consultants start?
Well, the short answer is nobody knows. It’s overwhelming at best and impossible at worst.
There are delivery and drug costs to reduce. There are Medicare abusers to root out. There are methods for predicting healthcare needs based on family history, lifestyle, and demographics to create. The high level check list goes on…and on. It’s scary.
There is good news in all the mess, however. First, the government is putting its money where its mouth is. As a part of the American Recovery and Reinvestment Act Obama shelled out $150 billion for healthcare. A large part of that is going to healthcare delivery (Medicare, insurance subsidies, etc) but there’s almost $30 billion in there for the sorts of work that analytical consultants make careers on. About 2/3 of that $30 billion is specifically for “health information technology”.
Now that’s a pretty vague and potentially broad bucket but, on the other hand, $20 billion can buy a lot of IT and consulting and that’s not including what the NIH (National Institute of Health) already has tucked away.
My feeling: start beefing up on healthcare and gas up your analytical engines. I’m not alone here. All the big firms have been moving to promote their own healthcare expertise in the last 6-12 months. Using numbers to fix healthcare is officially en vogue. The question I’m interested in answering is where are the big breakthroughs, analytically speaking, going to come in all this?
Thursday, July 9, 2009
More to come: Crowd-sourced wine?
At the risk of sounding "unofficial," I would like to post an entry about an entry I intend to post after I have thought this through better. Isn't that the point of this?
I think that there is a good business model out there to be executed around crowd-sourced wine. I think bringing the consumers and the vendors together makes a lot of sense, and at its simplest it solves 2 simple problems:
I think that there is a good business model out there to be executed around crowd-sourced wine. I think bringing the consumers and the vendors together makes a lot of sense, and at its simplest it solves 2 simple problems:
- Restaurants and retail stores have facilities to store wine properly but have to carry the cost of their inventory before wine is sold--inventory is a bad thing
- Restaurant and retail consumers generally don't have facilities to store wine properly but want to amass a wine "collection" for which inventory is a good thing
I need to research the state of wine blogs and wine consignment before saying anything intelligent about this, but I think that if you married the two, you could improve on the "wine locker" approach employed by some restaurants in which regular customers store their own wines at restaurants.
What if, for example, I stored 4 cases of Opus at Grill 23 in Boston. When I was in for dinner, perhaps I open one of "my" bottles with an upcharge or corkage fee. But what if the restaurant is able to sell my wine, pay me what they pay their distributor, but they don't OWN the wine until it is sold? The restaurant loses the inventory carrying cost, the customer has a great place to store wines, can access them any time, and the customer even has a revenue stream!
The crowd-sourcing side of this, of course, is that a restaurant could have a wine list that is essentially the sum of its participating customers' collections. And who knows better what wines a restaurant's customers like than the customers? Plus, build a community and all of a sudden you have restaurants getting regulars simply BECAUSE they participate. You get groups of individuals all storing wine at a given restaurant coming together organically to do tastings at that restaurant, to swap wines, to swap stories. Break down the barrier between online community and offline community...over a glass of wine no less.
Issues to resolve include the legal side, the restaurant operations aspect, and I am sure myriad others, but for each one of those, there are five upsides to the person who puts this model to work.
- Build out a site to manage all this inventory, and you are linking restaurants/retail with customers, and there is money in that
- Link to reviews and other intellectual property and there is money in that
- Always the advertising--no different here
- Create a COMMUNITY in which people can talk about, rate, discuss, buy, sell, and enjoy wine; by crowd-sourcing the content, you cna relinquish control to collaborative participation and just be the "connector"
- Go upstream down the road and help restaurants with their wine inventory; write standard and custom "reports" as dynamicly printed wine lists (daily, weekly?)
- Down the road, is there such a thing as a digital wine list on a netbook? Customers flip through the inventory with reviews, tasting notes, pairings, and other content right at hand?
- I bet a bottle of wine, 3 people, 45 minutes, and a white board is all it would take to come up with 10 other meaningful revenue streams.
Again, there is plenty of room for more content here, but I think it is a powerful business model, and perhaps one worth fleshing out.
Wednesday, July 8, 2009
How I learned to stop worrying and love the cloud
If the recent feverish popularity of netbooks hadn't given you any indication of the permanence of cloud computing, Google's recent announcement should help drive the point home. Most of us internet users use various clouds (e.g. GMail, Facebook) all the time without even realizing it -- part of the beauty of the cloud. As a user, I don't need to worry data storage, program installation, or the risk of equipment failure. I can let specialized organizations manage all those decisions for me, and focus on my priorities. Many businesses are doing just that.
While some are still questioning whether cloud computing it just the latest tech buzzword soon to be fitted with the prefix 'e' or the update '2.0', the computer and business world are seeing cloud computing as a major factor in their respective industries. You want to build your own cloud? Thank goodness for capitalism. Major hardware companies like Dell are pushing infrastructure solutions, while IBM and HP offer blended hardware and software packages. But why own a cloud when you just want to use one? I don't want to buy a chicken, just because I want a few eggs.
Enter Amazon Web Services(AWS), a clear front-runners of cloud computing. AWS has set up a host of offerings enabling individuals and businesses to buy ad hoc computing power and select services. Most obvious is the ability for large corporations to take advantage of the cloud and simplify their IT management, increase workplace collaboration, and better manage their IT spending. But it's really the cash-conscious start-ups that are able to catapult their offerings by leveraging cloud technology.
A great example of this is Animoto's launch of their Facebook application in April 2008. Within a few days 750,000 signed up for the service. Fortunately for the employees, they did not have to stay up day and night installing additional capacity or sit in front of a microwave nuking up hot pockets to fuel said late night installs. Animoto's founders didn't have the money or the expertise to run a server farm, so they signed up with AWS for 50 virtual machines. With the demand spike from the Facebook application launch, they were able to ratchet that up to 3,500 virtual machines with nothing more than a phone call. When the demand subsided, they throttled back the number of virtual machines.....and the cost.
We see the cloud providers as clear winners in this, leveraging economies of scale and smoothing demand across users to turn a profit. Business users benefit as well by joining a cloud as they can be faster to market with IT capabilities, leverage n level technology, and turn Capex into Opex. What's the catch? With the centralization of data and lack of physical storage ownership, privacy becomes more of an issue. While not a roadblock yet, there is much room for though leadership in this area. Perhaps this is a topic for another post.
Thanks to the cloud, market barriers just got a little bit lower. Now, let the competition begin.
Tuesday, July 7, 2009
OLAP for the masses
Summary
XLCubed is a strong option when it comes to finding user-friendly ways to deploy OLAP technology.
What could be better: integration with other multidimensional sources besides SSAS, version controlling in the local edition, more formatting options
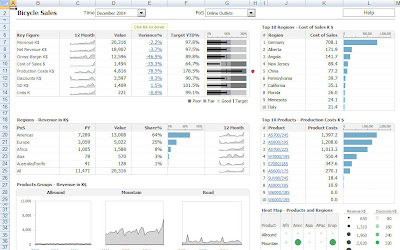 A finished XLCubed dashboard using the Adventure Works OLAP cube
A finished XLCubed dashboard using the Adventure Works OLAP cube
The business
Business Intelligence junkies have no shortage of words when it comes to describing the wonders of OLAP technology and the end-consumers of that technology, typically those in some position of management, love what they see. “Slicing and dicing”, “drilling”, “drag and drop”; multi-dimensional data browsing is a proverbial candy store to data hounds everywhere. It is unsurprising, then, that virtually every BI vendor of note has made a point of pushing its own flavor of the technology.
 To start, users are presented with all the data available to them in a friendly GUI that resembles a pivot table creation screen. They can drag and drop data across columns, rows, or headers and populate the values with whatever measures they may wish. For hierarchical data (e.g. dates) selecting a level to default the report to is as simple as expanding the familiar Windows Explorer-esque “[+]” box next to a data field and selecting something below.
To start, users are presented with all the data available to them in a friendly GUI that resembles a pivot table creation screen. They can drag and drop data across columns, rows, or headers and populate the values with whatever measures they may wish. For hierarchical data (e.g. dates) selecting a level to default the report to is as simple as expanding the familiar Windows Explorer-esque “[+]” box next to a data field and selecting something below.

In the report users can continue to drag data elements around, just like in a pivot table, and the report will refresh without losing any functionality or calculated columns or rows that have been manually added (unlike a pivot table). The sheet can be formatted using normal Excel formatting and, all of a sudden, with almost no extra training or knowledge the Excel user has a custom Excel report or model but this time based on centrally stored and maintained data.
To address issues of security and version control the guys at XLCubed also created a web-version. With an extra license users can upload anything they create to a central website (intranet or extranet) and it will become available to anyone with access rights which, conveniently, are administered on a user-level basis. Most impressive, however, is how similar the web-based reports look to those sitting on a local instance of Excel. The functionality it almost identical, including navigation, which is key. Users can manipulate what others have created, take reports offline, or simply start from scratch, assuming they have the security clearance.
The point here is not to create an exhaustive account of all of XLCubed’s functionality. For that their website is a good resource (http://www.xlcubed.com/) as are their introductory tutorial videos on YouTube (simply search for XLCubed). Instead we simply want to draw attention to the fairly basic and yet seemingly difficult to solve problem that XLCubed has addressed: user uptake.
We would never suggest that any software is without drawbacks either and for all of its virtues, XLCubed is no exception. For starters, it is currently only compatible with the Microsoft stack. That is to say, it requires data to be stored in a Microsoft Analysis Services cube. While it’s not picky about SSAS versions (it will take SSAS 2000, 2005, or 2008) this is obviously limiting for any organization that doesn’t run a SQL Server back end.
XLCubed also doesn’t fully solve the spreadsheet-farm problem that many organizations are grappling with when they turn to BI. It’s a bit misleading to categorize this as a shortcoming both because the whole point of the software is to keep users in Excel and because the web edition does, by and large, address the issue. Nonetheless, anytime users are manipulating data locally there is risk of a knowledge gap (or worse, conflicting versions of the truth) developing and this doesn’t go away with XLCubed.
So at the end of the day XLCubed isn’t revolutionary in what it allows users to do. Everyone can provide calculations on the fly, hierarchical data browsing, and dimensional reporting. Everyone preaches improved data quality and accuracy. While XLCubed provides all that, it certainly isn’t the best at any of it.
What XLCubed does with distinction, however, is to make that functionality easily available to anyone that can use Excel. Gone are the weeks of training, endless calls to the support desk, and user manuals that would seem fit for the latest models of nuclear submarines. Instead, new users are faced with supplementing their tried-and-true methods for analysis and reporting with a couple of extra buttons and one drop-down menu. Most importantly, everything is within a framework that users are already comfortable with so adding to it, instead of replacing it, is refreshingly simple.
To sweeten the package, local edition licenses for XLCubed move for well under $1000/license. The server licenses are equally competitive starting at around $15k for 10 concurrent users. Granted an OLAP engine will be needed for the source but, even for those few companies that don’t already have some sort of SQL server or other enterprise data solution, the price tag for XLCubed almost invariably comes in substantially below a full BI stack.
XLCubed is a strong option when it comes to finding user-friendly ways to deploy OLAP technology.
What we like: seamless Excel integration, full Excel functionality, compatibility with Excel 2003 or 2007, drag and drop reporting, calculated members created directly in Excel cells with the regular formulas, Microcharts, web posting, ease of use
What could be better: integration with other multidimensional sources besides SSAS, version controlling in the local edition, more formatting options
{kind=link} A finished XLCubed dashboard using the Adventure Works OLAP cube
A finished XLCubed dashboard using the Adventure Works OLAP cubeThe business
Business Intelligence junkies have no shortage of words when it comes to describing the wonders of OLAP technology and the end-consumers of that technology, typically those in some position of management, love what they see. “Slicing and dicing”, “drilling”, “drag and drop”; multi-dimensional data browsing is a proverbial candy store to data hounds everywhere. It is unsurprising, then, that virtually every BI vendor of note has made a point of pushing its own flavor of the technology.
Microsoft offers Analysis Services. Cognos picked up TM1. Microstrategy has its proprietary analysis module. QlickTech has...well, everything they offer. Whether it’s a traditional OLAP cube, in memory processing, or a proprietary ROLAP engine, any BI solution without it is incomplete. So why doesn’t everyone have it?
As The Data Warehouse Institute, the Aberdeen Group, and Gartner all point out, one of the leading causes of failure in business intelligence solution deployments is a lack of uptake among staff of the new technology. With all due respect to the three research groups, this “finding” is hardly insightful to anyone who’s been involved even tangentially with BI. The reality is the vast majority of the users of BI solutions are not particularly technical themselves. What they are is busy and less than enthralled with the idea of learning to use new pieces of software, such as those offered by the aforementioned BI giants. Enter XLCubed.
XLCubed is a plug-in for Microsoft Excel – the business world’s ubiquitous data analysis platform. It allows users to connect directly to an OLAP cube through their trusted front-end with just a few clicks. Upon connection, the already familiar Excel functionality is supplemented with the power of OLAP.
 To start, users are presented with all the data available to them in a friendly GUI that resembles a pivot table creation screen. They can drag and drop data across columns, rows, or headers and populate the values with whatever measures they may wish. For hierarchical data (e.g. dates) selecting a level to default the report to is as simple as expanding the familiar Windows Explorer-esque “[+]” box next to a data field and selecting something below.
To start, users are presented with all the data available to them in a friendly GUI that resembles a pivot table creation screen. They can drag and drop data across columns, rows, or headers and populate the values with whatever measures they may wish. For hierarchical data (e.g. dates) selecting a level to default the report to is as simple as expanding the familiar Windows Explorer-esque “[+]” box next to a data field and selecting something below.
Once happy with the layout of the report, the user clicks “Insert” and they’re off to the races. A grid report, as it is referred to in XLCubed lingo, is immediately placed into the open Excel sheet. Users can double click on any hierarchical data and the entire report will expand.
double click on any hierarchical data and the entire report will expand.
 double click on any hierarchical data and the entire report will expand.
double click on any hierarchical data and the entire report will expand.In the report users can continue to drag data elements around, just like in a pivot table, and the report will refresh without losing any functionality or calculated columns or rows that have been manually added (unlike a pivot table). The sheet can be formatted using normal Excel formatting and, all of a sudden, with almost no extra training or knowledge the Excel user has a custom Excel report or model but this time based on centrally stored and maintained data.
To address issues of security and version control the guys at XLCubed also created a web-version. With an extra license users can upload anything they create to a central website (intranet or extranet) and it will become available to anyone with access rights which, conveniently, are administered on a user-level basis. Most impressive, however, is how similar the web-based reports look to those sitting on a local instance of Excel. The functionality it almost identical, including navigation, which is key. Users can manipulate what others have created, take reports offline, or simply start from scratch, assuming they have the security clearance.
The point here is not to create an exhaustive account of all of XLCubed’s functionality. For that their website is a good resource (http://www.xlcubed.com/) as are their introductory tutorial videos on YouTube (simply search for XLCubed). Instead we simply want to draw attention to the fairly basic and yet seemingly difficult to solve problem that XLCubed has addressed: user uptake.
We would never suggest that any software is without drawbacks either and for all of its virtues, XLCubed is no exception. For starters, it is currently only compatible with the Microsoft stack. That is to say, it requires data to be stored in a Microsoft Analysis Services cube. While it’s not picky about SSAS versions (it will take SSAS 2000, 2005, or 2008) this is obviously limiting for any organization that doesn’t run a SQL Server back end.
XLCubed also doesn’t fully solve the spreadsheet-farm problem that many organizations are grappling with when they turn to BI. It’s a bit misleading to categorize this as a shortcoming both because the whole point of the software is to keep users in Excel and because the web edition does, by and large, address the issue. Nonetheless, anytime users are manipulating data locally there is risk of a knowledge gap (or worse, conflicting versions of the truth) developing and this doesn’t go away with XLCubed.
So at the end of the day XLCubed isn’t revolutionary in what it allows users to do. Everyone can provide calculations on the fly, hierarchical data browsing, and dimensional reporting. Everyone preaches improved data quality and accuracy. While XLCubed provides all that, it certainly isn’t the best at any of it.
What XLCubed does with distinction, however, is to make that functionality easily available to anyone that can use Excel. Gone are the weeks of training, endless calls to the support desk, and user manuals that would seem fit for the latest models of nuclear submarines. Instead, new users are faced with supplementing their tried-and-true methods for analysis and reporting with a couple of extra buttons and one drop-down menu. Most importantly, everything is within a framework that users are already comfortable with so adding to it, instead of replacing it, is refreshingly simple.
To sweeten the package, local edition licenses for XLCubed move for well under $1000/license. The server licenses are equally competitive starting at around $15k for 10 concurrent users. Granted an OLAP engine will be needed for the source but, even for those few companies that don’t already have some sort of SQL server or other enterprise data solution, the price tag for XLCubed almost invariably comes in substantially below a full BI stack.
Wednesday, July 1, 2009
Transparency for the Federal Government...done and done
I am having trouble explaining the magnitude for my excitement about the federal government's massive entres into data transparency. In no time at all, Vivek Kundra has helped Obama and Co. rewrite the rules around the way the public sector looks at information and accountability.
Take www.usaspending.gov. For years, we consultants have worked with organizations public and private to address spending. "Strategic Sourcing," as the phrase was coined by A.T. Kearney veterans, runs into the same barrier 9 times out of 10. Someone in purchasing has a bad contract, and the client is paying 50% more than they should be for staples or laptops or asphault for roads, but for one reason or another, they don't want to shake that contract. In the public sector, the problem is 10x because public sector employees are not as directly incentivized by the bottom line. They are, however, motivated by public opinion.
So by posting all these contracts online, we get a chance to see that the "Cheyenne Mountain Complex/Integrated Tactical Warning /Attack Assessment," a defense contract out to Lockheed Martin for $26.1M in 2009 spending (and it would be great to know the total contract value) has a contract variance of 167.84% and an average of 120 days late per milestone. I am not saying we don't need this project, but I am pleased that it's variance to plan is online and that as more citizens clue into these variances, those responsible for their delivery will no doubt tighten the reigns, when before they could proceed business-as-usual, the public none the wiser.
Add to this excitement my boundless energy for data.gov, a perhaps more ambitious project over which plenty of blog ink has been spilt. And better bloggers than I at that. The core of the concept, is taking what information is available and public...and making it available and public and accessible. What really matters to me is that there are massive implications for management consultants, data analysts, and the quantitative community at large who are paying attention. Entire business can and will be built around taking this now-accessible information, digesting it, and making it useful for businesses. Our President and our Federal CIO have taken the first step, and now it is our task to take the next.
What an exciting time it becomes as a result.
Take www.usaspending.gov. For years, we consultants have worked with organizations public and private to address spending. "Strategic Sourcing," as the phrase was coined by A.T. Kearney veterans, runs into the same barrier 9 times out of 10. Someone in purchasing has a bad contract, and the client is paying 50% more than they should be for staples or laptops or asphault for roads, but for one reason or another, they don't want to shake that contract. In the public sector, the problem is 10x because public sector employees are not as directly incentivized by the bottom line. They are, however, motivated by public opinion.
So by posting all these contracts online, we get a chance to see that the "Cheyenne Mountain Complex/Integrated Tactical Warning /Attack Assessment," a defense contract out to Lockheed Martin for $26.1M in 2009 spending (and it would be great to know the total contract value) has a contract variance of 167.84% and an average of 120 days late per milestone. I am not saying we don't need this project, but I am pleased that it's variance to plan is online and that as more citizens clue into these variances, those responsible for their delivery will no doubt tighten the reigns, when before they could proceed business-as-usual, the public none the wiser.
Add to this excitement my boundless energy for data.gov, a perhaps more ambitious project over which plenty of blog ink has been spilt. And better bloggers than I at that. The core of the concept, is taking what information is available and public...and making it available and public and accessible. What really matters to me is that there are massive implications for management consultants, data analysts, and the quantitative community at large who are paying attention. Entire business can and will be built around taking this now-accessible information, digesting it, and making it useful for businesses. Our President and our Federal CIO have taken the first step, and now it is our task to take the next.
What an exciting time it becomes as a result.
Tuesday, June 30, 2009
On crowd-sourced analytics
The analytics community is a powerful but fragmented one, and that is both good and bad. Good in the sense that for all intents and purposes, every meaningful challenge in the business community has already been solved in one place or another. Bad in the sense that no one of us shows up Monday morning with any more than perhaps 30% of that collective toolset at the ready...at best.
So what do we "quant blue shirts" do when we encounter intractable business problems in our management consulting lives? We reach out to our limited network, and we cobble together the best solution we can given what's been done before, periodically innovating in the margins and typically producing incremental value add. Tight project timelines don't often allow for truly white space analytical thinking, but we get by alright. Thrillin' and billin', right?
These tight timelines, however, have always made management consultancies poor at collecting and leveraging intellectual capital. More devastatingly, there is a culture, particularly among top tier management consultants, to create but not to use intellectual capital. If rewards are given for creating the next great thing, scorn is cast on those poor plebs who, the next week, use what was discovered on another project. And so IC is cast into the abyss of some arcane, mystic IC tracker, like the warehouse from Raiders of the Lost Ark, never to be seen again, next month's IC award go to someone in the Milan office who unknowingly created from scratch a tool or approach that was solved years ago in the Tokyo office (or perhaps in the Milan office).
I would posit for the group that crowd-sourcing analytics is one answer. When an cagey problem arises, it should immediately and without scorn be thrown to the community, who can and will consume it like a swarm of locusts. The collective memory and capability of the community is as sinewy and agile as Ajax (the Homeric Greek, not the language, though perhaps both apply?). The rule of the road will be, "solve problems in your wheelhouse (yours and others') and throw the rest to the group.
I would take this a step further, however, and lay down the claim that the academic community needs to be closer to these problems. (Yes, I said it.) I think the "community" should include students. I remember, as a student, flying through Multivariable Calculus exams that today would make my head spin, and I know that my peers are nodding when it comes to other quantitative methods like econometrics or applies statistics. Even a shaky solution to a simple consumer polling challenge could be corrected with swift precisoin a freshman undergrad who happens to be on that chapter.
And why would they log on in the first place? There's no better way to understand how to apply their academic concepts than to apply them, and there is something appealing about seeing your own wizardry at work in the real world. Plus, students want jobs, and they want jobs they like. Log onto a site from time to time and interact with these blue shirts--you'll see if it's for you, if you like the work in the trenches and if you like the people, the pace, the culture.
For you skeptics, I imagine there are two major hurdles, so let's hash them out. First, everyone wants to hoarde and silo IC, and we even have issues around postings of protected intellectual property. Clearly there needs to be an understanding around client confidentiality. Our clients don't want their analytical laundry aired, and consulting firms don't want their chief value distributed. Both of these, I believe, are manageable. Don't post anything confidential, and don't post anything protected. Most challenges are abstract enough that I feel we can cross that bridge when we get there. And if the problem originates in the community, the solution is one from the community. Information wants to be free anyway, and the realists out there are getting eroded.
The second challenge is that if we blue shirts making hay are leveraging insight from the academic community as well as our peer community, there could emerge the perception that consultants are looking for free labor, getting paid for other people's insight. I don't think this is the point, though I acknowledge it is something for which to look out. The point is to create a symbiotic community. Students get closer to real world challenges and areas to apply their skills and talents, as well as a forum outside of recruiting for interacting with those people with whom they may later choose to work. There's no better way to understand the work that consultants are doing than to dig in on some of their problems and interact with the personalities. Not everyone will want to get involved, but that's true of anything, so let's put it out there and see who picks it up.
Ok, brass tacks. I see two next steps coming out of this. First, we give it a try by posting real questions to real problems on this site, and we start the dialogue today--then see what happens. At the same time, I would be keen to get everyone's perspective on this, students, professors, consultants, would-be clients...
(This effects everyone.)
So what do we "quant blue shirts" do when we encounter intractable business problems in our management consulting lives? We reach out to our limited network, and we cobble together the best solution we can given what's been done before, periodically innovating in the margins and typically producing incremental value add. Tight project timelines don't often allow for truly white space analytical thinking, but we get by alright. Thrillin' and billin', right?
These tight timelines, however, have always made management consultancies poor at collecting and leveraging intellectual capital. More devastatingly, there is a culture, particularly among top tier management consultants, to create but not to use intellectual capital. If rewards are given for creating the next great thing, scorn is cast on those poor plebs who, the next week, use what was discovered on another project. And so IC is cast into the abyss of some arcane, mystic IC tracker, like the warehouse from Raiders of the Lost Ark, never to be seen again, next month's IC award go to someone in the Milan office who unknowingly created from scratch a tool or approach that was solved years ago in the Tokyo office (or perhaps in the Milan office).
I would posit for the group that crowd-sourcing analytics is one answer. When an cagey problem arises, it should immediately and without scorn be thrown to the community, who can and will consume it like a swarm of locusts. The collective memory and capability of the community is as sinewy and agile as Ajax (the Homeric Greek, not the language, though perhaps both apply?). The rule of the road will be, "solve problems in your wheelhouse (yours and others') and throw the rest to the group.
I would take this a step further, however, and lay down the claim that the academic community needs to be closer to these problems. (Yes, I said it.) I think the "community" should include students. I remember, as a student, flying through Multivariable Calculus exams that today would make my head spin, and I know that my peers are nodding when it comes to other quantitative methods like econometrics or applies statistics. Even a shaky solution to a simple consumer polling challenge could be corrected with swift precisoin a freshman undergrad who happens to be on that chapter.
And why would they log on in the first place? There's no better way to understand how to apply their academic concepts than to apply them, and there is something appealing about seeing your own wizardry at work in the real world. Plus, students want jobs, and they want jobs they like. Log onto a site from time to time and interact with these blue shirts--you'll see if it's for you, if you like the work in the trenches and if you like the people, the pace, the culture.
For you skeptics, I imagine there are two major hurdles, so let's hash them out. First, everyone wants to hoarde and silo IC, and we even have issues around postings of protected intellectual property. Clearly there needs to be an understanding around client confidentiality. Our clients don't want their analytical laundry aired, and consulting firms don't want their chief value distributed. Both of these, I believe, are manageable. Don't post anything confidential, and don't post anything protected. Most challenges are abstract enough that I feel we can cross that bridge when we get there. And if the problem originates in the community, the solution is one from the community. Information wants to be free anyway, and the realists out there are getting eroded.
The second challenge is that if we blue shirts making hay are leveraging insight from the academic community as well as our peer community, there could emerge the perception that consultants are looking for free labor, getting paid for other people's insight. I don't think this is the point, though I acknowledge it is something for which to look out. The point is to create a symbiotic community. Students get closer to real world challenges and areas to apply their skills and talents, as well as a forum outside of recruiting for interacting with those people with whom they may later choose to work. There's no better way to understand the work that consultants are doing than to dig in on some of their problems and interact with the personalities. Not everyone will want to get involved, but that's true of anything, so let's put it out there and see who picks it up.
Ok, brass tacks. I see two next steps coming out of this. First, we give it a try by posting real questions to real problems on this site, and we start the dialogue today--then see what happens. At the same time, I would be keen to get everyone's perspective on this, students, professors, consultants, would-be clients...
(This effects everyone.)
Subscribe to:
Posts (Atom)